Blog
The most useful thing about a deal is what changed
Why an engine that learns which changes matter has to learn from a whole population of deals, not from rules written for one.
A deal summary tells you where a deal stands. That is close to the least useful thing you can know about it.
You already know where your deals are. Stage, amount, last touch. A summary answers where the deal is, and you can usually answer that yourself. The question that actually changes what you do today is harder: what moved since you last looked, and how much does it matter.
Take two deals that are identical in a summary. Both in negotiation, both 48k, both active this week. One has a champion replying faster than they did a month ago, a second stakeholder pulled into the thread, your own pricing language coming back at you in their emails. The other has a champion who went quiet right after the pricing call and a new legal contact who has not answered. The row in your CRM is the same for both. One is closing. One is dying.
State is a photograph. A deal is a video. A photo of a deal mid-fall looks the same as one mid-climb. You only learn direction by comparing frames. So the unit that matters is not the state of the deal, it is the change between two readings of it.
Most change is noiseLink to heading
Here is where it gets harder, and where most tools stop. Knowing that change matters is easy. Knowing which change matters is the entire problem.
A moved calendar invite is a change. It is not a precursor of anything. A champion going quiet six days after a pricing conversation is also a change, and it precedes lost deals far more often than won ones. In a feed of recent activity the two look alike. In what they tell you they are nothing alike. So the object the engine actually cares about is not an event, it is a precursor: a change that tends to come before an outcome. A tripwire. And a precursor is more specific than champion went quiet. It is a combination of four things: what happened (the type of event), what the value was (reply latency moved from hours to days), over what window (within a week of the pricing call), and in which direction (cooling, not heating). Champion reply latency moved from hours to days within seven days of a pricing discussion is a precursor. Champion went quiet is a vibe.
You cannot write the weights by handLink to heading
Once you frame it as precursors, the next question is how much each one moves the odds. This is the part you cannot hand-code. The instinct is to write rules: if the champion goes quiet, flag the deal. But how much should that flag count? It depends. A quiet champion means one thing on a 30-day deal and another on a nine-month one. Reply latency that is alarming in week two is normal in week twelve. Any number you assign is a guess, and a static guess applied to every deal is wrong for most of them.
The only way to know how much a precursor actually matters is to have watched it play out across a large number of deals and counted what happened. This is the shift, and it has a name worth understanding: cross-entity learning. Most deal intelligence treats each deal as an island. It looks at this deal's own history and scores it. The problem is structural. A new deal has almost no history, so you get your weakest read exactly when you need it most, at the start, when you could still change the outcome.
Cross-entity learning inverts that. Instead of learning this deal's pattern, it learns the generalizable signal across the whole population of past deals, won and lost: when a champion goes quiet within N days of a pricing conversation, deals that look like this one go on to lose some measurable amount more often than the base rate. That pattern was learned from outcomes, not assumed. And because it is a pattern about a kind of moment rather than a specific deal, it transfers. A brand-new deal with three days of its own history can be scored against it on day one.
# learned from outcomes across the whole deal population:# for each precursor, how its presence shifts P(loss) vs the base rateprecursor_weight = learn_from_population(closed_deals) def rank_change(new_deal): # precursors are changes, not state: (event, value, window, direction) moved = detect_precursors(new_deal.recent_events) scored = [(p, precursor_weight[p]) for p in moved] # rank by how much each change moves the odds; the rest is noise return sorted(scored, key=lambda x: -x[1])That is the difference between a rule and a learned weight. A rule is someone's guess about how much a signal should count. A learned weight is the measured answer, taken from thousands of deals that already resolved. The engine is not matching this deal against itself. It is asking, of everything it has ever seen, what tends to precede a win and what tends to precede a loss, and scoring the change in front of it against that.
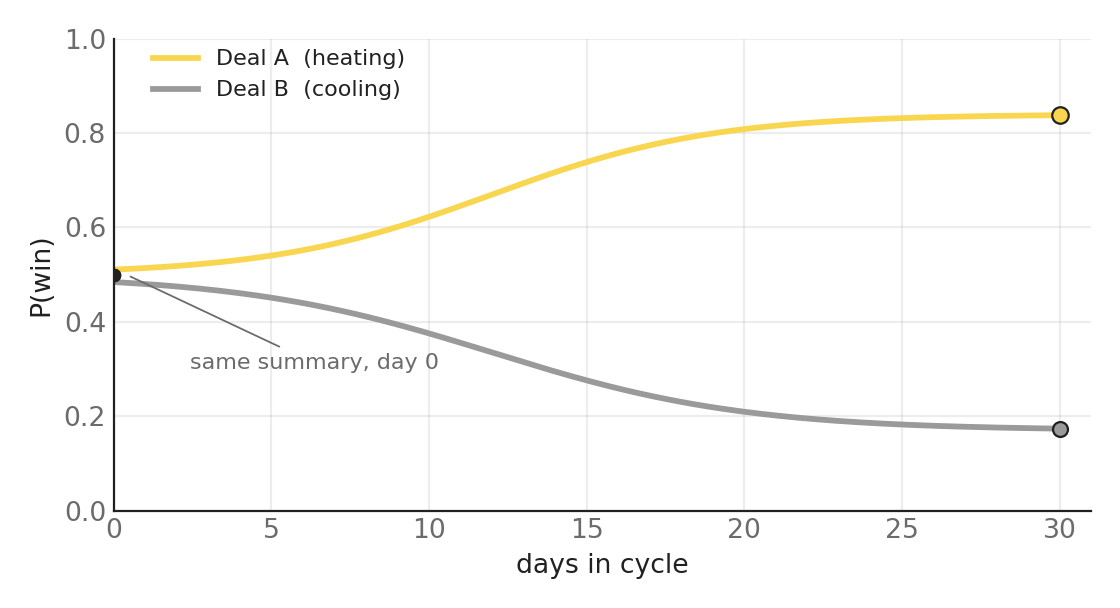
The plot is those two deals as probability instead of a summary row. They begin together because the summary is identical. They separate because the precursors are not. The yuzu line is the deal whose changes are weak precursors of winning; the grey line is the deal whose changes are strong precursors of losing. Neither line is visible in a CRM. Both are visible in the population.
So what you get before a call is not a recap. It is the two or three precursors that actually fired on this deal, ranked by how much each has shifted the odds across every deal like it, in the buyer's own words. State is easy, and any tool can show you state. Ranking change by learned impact is the part you cannot fake, and it is the part the engine is for.